横浜市立大学の土師達也助教らの研究グループは、OpenAI社のChatGPTに医学に関する質問をする際の注意点を科学的に検証した。文献数の差が正答率に大きな影響を及ぼしていることを突き止めた。
究グループは、日本の医師国家試験3年分をChatGPTに出題し、その正答率と回答の一貫性を集計した。
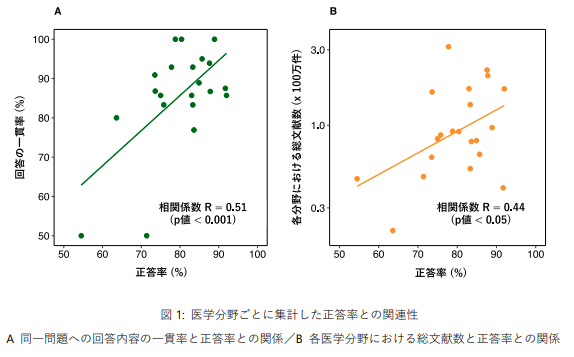
その結果、それぞれの医学分野においてこれまでに出版された文献数とChatGPTの正答率が有意な関連を示すことが分かった。ChatGPTの性能が、各分野における情報量の違いの影響を受けている可能性を示しており、情報量が乏しい分野に関して質問をする際には注意が必要と判明している。
研究グループは「医学に関する質問に対するChatGPTの性能と注意点の理解は、医学分野での実際の運用に加え、一般市民が日常の医学保健衛生上の問題解決や教育を促進していく上でも非常に有用と考えられる」とコメントした。